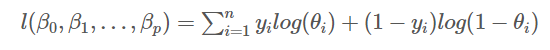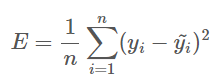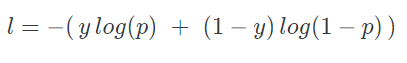개요
- 이번부터 쓰는 글은 Tensorflow-models 중 hand-pose-detection 을 자사 제품 내에서 구현한 후, 그와 관련된 AI 이론을 정리한 내용임
- 이번 글 출처: 학부 강의 내용, 필기, 구글링, 필요하다면 이하에서 출처 명시했음
1. 서
의미
- 2개 이상의 hidden layer를 가지고 있는 Neural Network 모형
→ 즉 2개 이상 = deep 하다 라고 생각하여 Deep Neural Network (이하 DNN) 라고 이름 붙여짐 - 그림

- hidden layer가 2개 이상인 이유
: 풀고자 하는 문제를 세부 문제로 나누고, 그 문제를 다시 세세부 문제로 나누기 때문
(ex) 사람의 얼굴인가 → 오른쪽 위에 눈이 있는가 → 위에 눈썹이 있는가, 가운데에 눈동자가 있는가, 아래에 속눈썹이 있는가
Support vector machine과의 비교
- SVM (Support Vector Machine)
- 머신러닝 분야 중 하나로 ①패턴 인식, 자료 분석을 위한 지도 학습 모델 분류와 ②회귀 분석을 위해 사용됨
- SVM의 패턴 인식 순서
- 2개 카테고리 중 어느 하나에 속한 데이터 집합이 주어졌을 때,
- 그것을 바탕으로 비확률적 이진 선형분류모델을 만듦. 이 모델은 새로운 데이터가 둘 중 어떤 카테고리에 속하는지 판단함
- 해당 모델은 데이터가 분포된 공간에서 선을 그어 경계를 표현함. 그리고 SVM 알고리즘은 그 중 가장 큰 폭을 가진 경계를 찾음
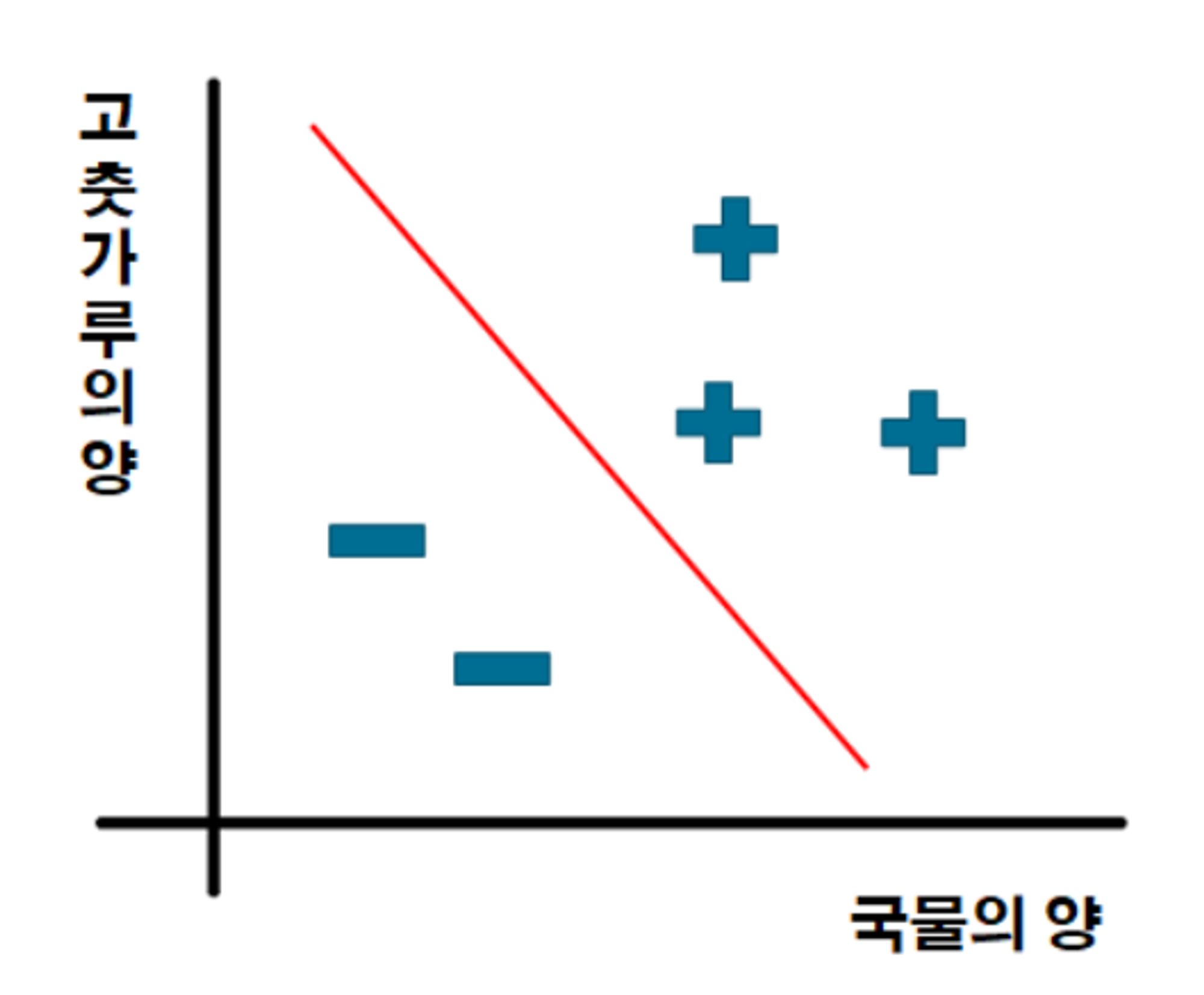
- 예시 : 이진 분류를 한다면 밑 사진처럼 직선(linear decision boundary)을 그어 구분하는 것
-> 출처: https://sanghyu.tistory.com/7
- 비교
| SVM | (D)NN | |
| 공통점 | - hidden feature 를 사용 - hidden space 위에서 linear decision boundary를 이용하여 분류 |
|
| 차이점 : 학습 대상 |
feature mapping은 고정, linear decision boundary만 학습 |
linear decision boundary + feature mapping 도 함께 학습 |
2. 모형
모수의 학습 방법
: 목적 함수 및 함수 구조를 기반으로 최적화 알고리즘 설명
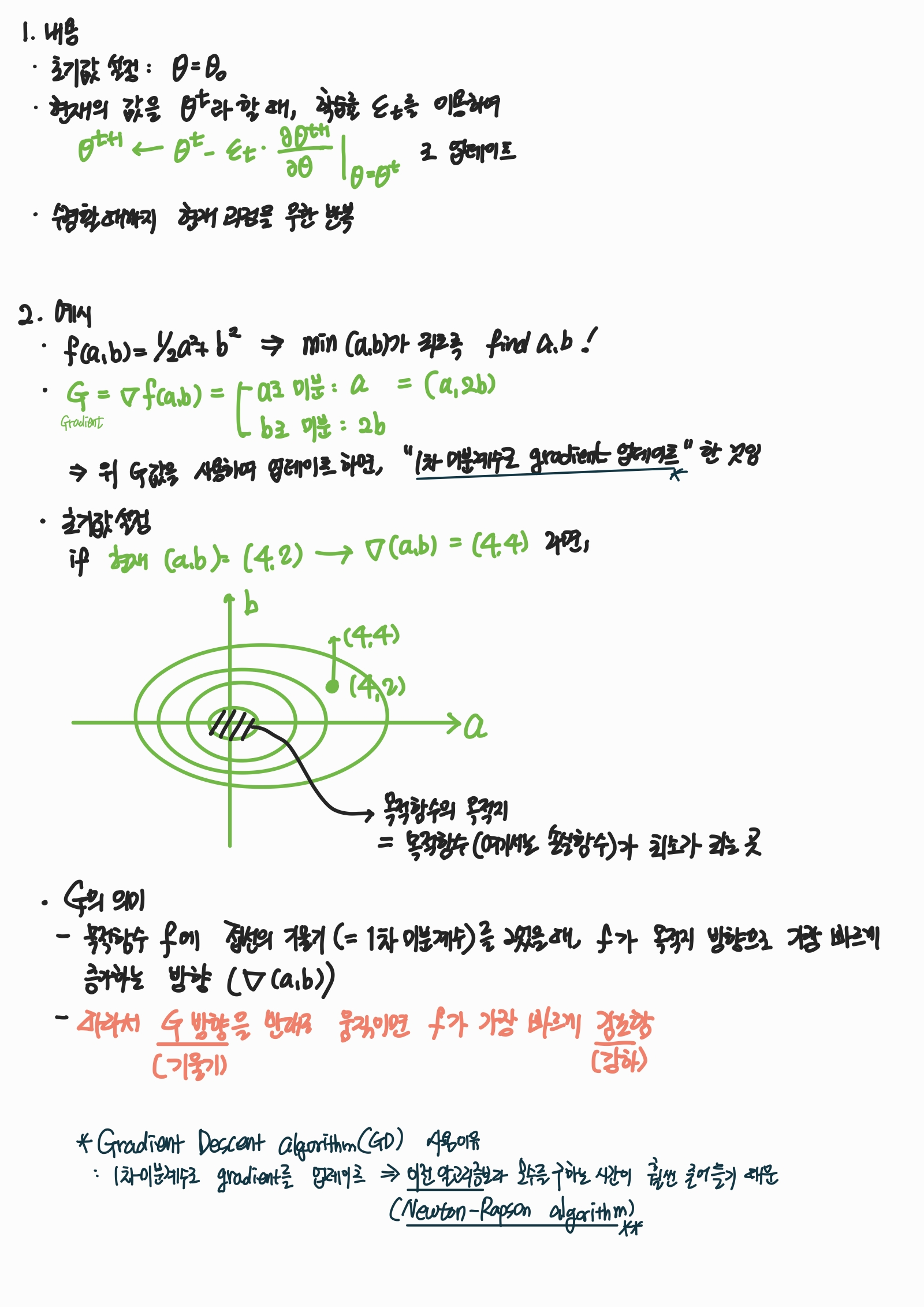
- 기울기 강화 알고리즘 (Gradient Descent algorithm; GD)
- 특정 목적 함수 L(θ)를 최소화하는 θ을 한 번에 찾기 힘든 경우에 사용하는 대표적인 반복 알고리즘.
- 목적 함수 의미


- GD의 아이디어

- 구체적인 알고리즘 내용

2. 역전파 알고리즘 (Back propagation algorithm)
- 의미
- 미분값이 위에서 아래로 계산되어짐 (Back propagation)
- DNN 모수들의 (b, w) gradient를 구하는 알고리즘
- 목적 함수 L(θ)을 최소화하기 위해 gradient descent algorithm을 사용한 결과,
NN의 특수한 형태 때문에 ∂L(θ) / ∂θ(l+1)의 계산에 필요한 값을 알고 있으면, ∂L(θ) / ∂θ(l)가 자동적으로 계산됨.
(여기서 θ(l)은 l층에서의 모수)
- 수식으로 의미 이해
- 실제 숫자를 넣어 gradient를 계산한 레퍼런스
https://wikidocs.net/37406 https://jaejunyoo.blogspot.com/2017/01/backpropagation.html - 나의 이해
- 실제 숫자를 넣어 gradient를 계산한 레퍼런스



- 예제
- 문제: Calculate gradient 에 있는 수식을 도출하는게 목적!



3. Stochastic gradient descent method (SGD)
- 기본 용어 정리
- Batch : 학습 데이터 전체
- Mini-batch : 학습 데이터의 일부, 즉 batch에서 sampling 한 것
- Epoch : 반복적인 학습 알고리즘을 사용할 때 모든 학습 데이터를 한 번 씩 사용하는 것을 의미
(ex: 10000개의 학습 데이터가 존재하고, 매번 50개의 데이터(i.e. 50개의 mini-batch)를 이용하여 모수를 학습할 때, 이 알고리즘을 200번을 반복하면 1 epoch, 400번을 반복하면 2 epochs라고 함.)
→ 즉 1 에폭당 학습 데이터 10000개를 한 바퀴 도는 느낌
- 의미
- Stochastic gredient descent algorithm을 사용한 method
- 아이디어 및 업데이트 방법


- 장점
- 계산량↓: 업데이트 할 때 모든 batch를 사용할 때보다 적은 계산을 필요로 함
- 정확성↑: 수렴성이 이론적으로 보장 (Bottou, 1998 and Murata, 1998)
- gredient descent algorithm과의 차이
- 핵심
- Gradient Descent (GD): mini batch 사용하지 않고 학습 → 에폭이 1인 SGD 느낌
- Stochastic Gradient Descent (SGD): mini batch 를 샘플링하여 학습 → 파생적으로 에폭의 개념 나오게 됨
- 수식
- GD
- 핵심
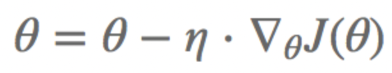
- SGD
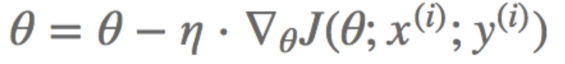
- 그림
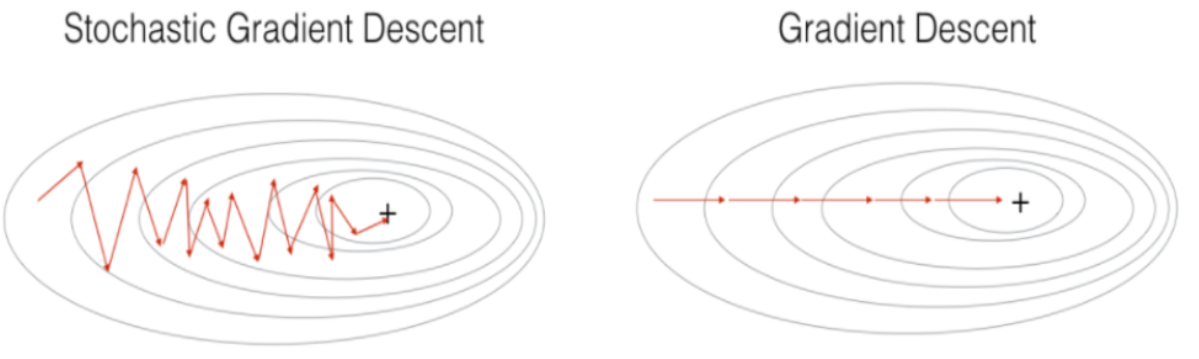
2. 학습률 (learning rate) 의 선택
의미
- 목적 함수의 최댓값 또는 최솟값을 향해 이동하면서 각 반복에서 단계 크기를 결정하는 스칼라
- 학습률은 머신러닝 및 통계학에서 사용되는 용어
- 최적화 알고리즘의 조정 매개변수
- εt∶ t 시점의 학습률
특징
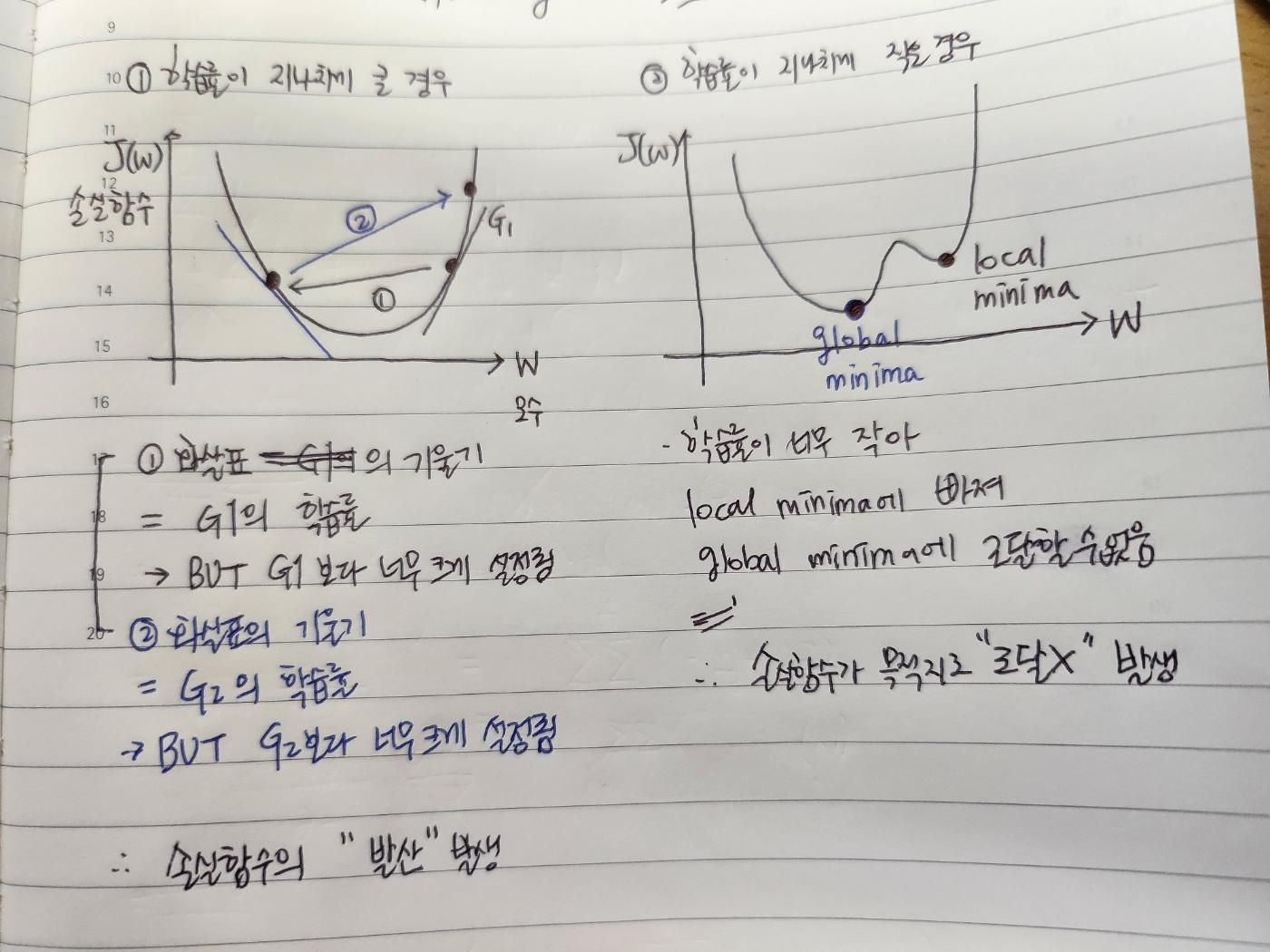
- 학습률이 지나치게 크거나 작으면 좋은 추정값을 얻을 수 없음. 목적 함수가 목적지로 발산 or 도달하지 못하기 때문임
- 따라서 학습이 진행될수록 비교적 큰 학습률 → t가 증가함에 따라 학습률을 줄여나가는 것이 바람직함
- 이론적으로는 εt ∝1/t이면 (비례하다면), 역전파 알고리즘을 사용하였을 때 손실 함수가 국소적인 최소값으로 수렴한다는 사실이 알려져 있음. (Bottou et al., 2018)
3. 한계
Vanishing gradients problem
- 모수에 대한 gradient 값이 아래층으로 내려갈수록 작아지는 현상.
= 즉, hidden layer 쌓을수록 추정 값 정확도↓ (=성능↓) - 그 결과 아래층의 모수가 초기 값과 크게 다르지 않은 값을 가진 채 학습이 종료.
= 즉, 안 좋은 모수를 갖는 추정 값으로 수렴함 - 따라서, 때때로 DNN이 NN 보다 성능이 나쁜 경우 발생함
- 원인: 역전파 알고리즘이 좋지 않은 추정값을 제공 (bad local minima).
Running time
- 일반적으로 DNN은 1개의 hidden layer를 가지는 NN보다 더 많은 수의 모수를 필요로 함
- 더 많은 수의 모수를 추정하기 위해 보다 더 많은 시간 소요됨
보완책: 사전 학습 (Pre-training)
- 2006년 G.E.Hinton 교수가 처음으로 제안: Hinton and Salakhutdinov (2006), Hinton et al (2006)
- 입력 변수만 사용하여 모수를 추정하는 기법 (Pre-training) → 추청된 모수를 학습 시 초기값으로 사용 (Training)
→ 이 방법이 이전 방법과 다른 이유: 기존 training은 입력 값, 출력 값을 모두 이용하여 학습 - 효과: 역전파 알고리즘의 한계 해결
- 결과가 해의 초기값에 의존
= 즉 아래층에 있는 모수들은 초기 값과 크게 다르지 않음 - 그러나 좋은 해의 초기값을 찾기 어려움
- 결과가 해의 초기값에 의존
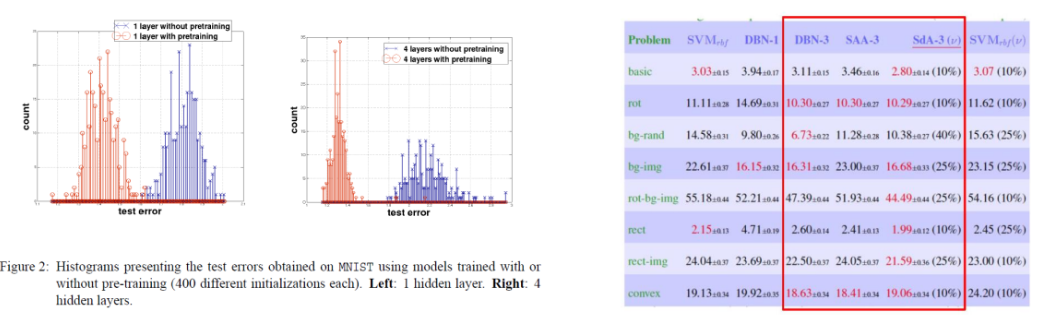
- 예시: Erhan et al., 2010 and Larochelle et al., 2007
- 왼쪽 그래프: hidden layer 1층, 오른쪽 그래프: hidden layer 4층
- hidden layer의 개수가 늘어날수록 pre-training 한 layer의 효과가 더 커짐
= 즉 데이터의 test error 가 작아짐
4. Advanced of deep learning
하드웨어의 발전: GPU의 사용
- 딥러닝에서 필요한 계산들을 대부분 병렬처리 가능
- 따라서 CPU로 계산할 때보다 훨씬 빠른 계산 가능
+ 훨씬 많은 hidden layer와 모수들을 가지는 복잡한 모형 설계하여 활용 가능
새로운 활성 함수의 개발: ReLU (Rectified Linear Units; Nair and Hinton (2010))
- 우수성
- 기존의 활성함수 (예: sigmoid or tanh)는 그 특성상 모수를 추정하는데 어려움
(어려움: vanishing gradient) - Piece-wise 선형 함수를 활성함수로 사용
→ vanishing gradient 문제 해결, 속도 향상, 사전 학습 불필요해짐
- 기존의 활성함수 (예: sigmoid or tanh)는 그 특성상 모수를 추정하는데 어려움
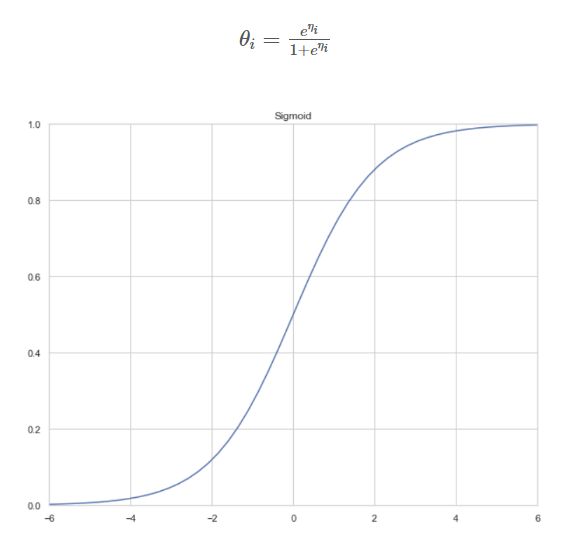
- sigmoid 함수와 비교

- 이후에 ReLU를 응용하여 LeakyReLU (Mass et al., 2013), PReLU (He et al., 2015), ELU (Clevert et al., 2015) 등 많은 활성 함수가 제안됨.
Regularization method 개발
- Drop out
- 매번 역전파를 할 때마다 노드의 절반을 끄고 (=drop out) 학습
→ 최종 결과를 낼 떄에는 각 층 결과값에 1/2를 곱하는 방법 - 효과: 노드 간 상관관계↓, 독립성↑
- 원인: fully connected neural network을 학습할 때, 같은 층의 노드간에 높은 상관관계 발생
→ 입력값이 조금만 바뀌어도 모든 네트워크에 큰 변화가 생길 수 있음
- 매번 역전파를 할 때마다 노드의 절반을 끄고 (=drop out) 학습
- Batch normalization
- 매번 mini batch를 이용하여 학습할 떄마다 노드들을 정규화함
- 효과: 적은 에폭 학습을 하여도 기존보다 좋은 성능 (ex. 보다 높은 accuracy)를 얻을 수 있게 됨
- 원인: 은닉 노드 각각의 분포 및 scale이 상이 → 성능이 좋지 않음
- Data augmentation (데이터 증강)
- Random crop, RGB perturbation, image reflection 등으로 학습 데이터를 대량 확보하는 것
- 심지어 Sequential data에서도 data의 순서를 바꾸어 학습 데이터를 늘림.
- 효과: 모델이 정확한 예측을 하기 위한 재료가 다수 확보됨
→ 보다 정확한 예측 가능 - 원인: 학습 대상 데이터의 양이 지나치게 적은 경우, 학습이 제대로 되기 어려움
- Residual learning architecture (잔차 학습 아키텍처)
- Networks에서 이웃하지 않은 layer 사이에도 connection을 추가
- 효과: Vanishing problem 해결
5. Advanced of learning algorithms
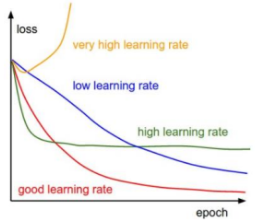
SGD 방법의 단점
- 학습률 εk의 scale에 따라 성능이 크게 좌우됨.
= 손실 함수들마다 좋은 성능을 보장하는 학습률 scale이 달라 선택이 어려움
2. 이전 gradient 정보들은 무시하고 현 시점의 gradient만을 사용하여 업데이트
→ 수렴 속도가 느릴 수 있음
3. 시점 k에서 모든 gradient에 미리 정해 놓은 학습률 εk를 곱해주어 업데이트.
→ 손실함수가 특정 모수들의 방향에 대해서 민감하게 변할 경우에 수렴하지 않을 수 있음.
→ 안장점*에 빠질 가능성이 높음.
* 안장점 (Saddle point)
- 다변수 함수에서 특정한 형태의 극값.
= 한 쪽 방향에서 보면 극댓값, 다른 쪽 방향에서 보면 극솟값
- 예시 : 이차항이 마이너스인 이차함수
-> 안장점 (이자 극댓값)에서 한 방향에서는 곡면이 상승, 다른 방향에서는 하강

- 머신러닝에서의 안장점
> 신경망 모형(NN)을 학습시킬 때 최적화 알고리즘이 안장점에 도달한 경우,
여기서 멈추지 않고 전역 최소점 (global minimum) 또는 국소 최소점 (local minimum) 에 도달할 수 있도록 설계해야함
( ∵ 최적화 알고리즘의 목표 = 목적함수(손실함수) 최소화)
> 따라서 이것이 머신러닝 또는 딥러닝의 성능을 결정지음
SGD with momentum
- 현 시점의 gradient 업데이트 방향이 이전 시점의 gradient 정보에 영향을 받는 방법
= 즉 현재 및 과거 시점의 gradient 크기에(g) 영향을 받아서 모수들(θ) 각각의 학습률이(ε) 결정됨 - Goodfellow, I., et al. (2016) Deep Learning : 모멘텀을 수식으로 증명

- 이는 “이전 gradient 정보들은 무시하고 현 시점의 gradient만을 사용하여 업데이트” 하는 SGD의 1번 단점을 보완한 것
adam
- ①accumulated squared gradient를 weighted average로 업데이트 함 (두 번째 빨간 박스)
+ ②현 시점의 gradient 업데이트 방향이 이전 시점의 gradient 정보에 영향을 받아 결정됨 (첫 번째 빨간 박스)
= ①RMSProp* + ②momentum- RMSProp (Tieleman and Hinton, 2012)
- AdaGrad*와는 다르게 accumulated squared gradient를 누적 합으로 업데이트 하지 않고, weighted average로 업데이트 함.
= 즉 AdaGrad의 단점 보완 - Goodfellow, I., et al. (2016) Deep Learning : RMSProp을 수식으로 증명
: 빨간 박스 수식 = weighted average
- AdaGrad*와는 다르게 accumulated squared gradient를 누적 합으로 업데이트 하지 않고, weighted average로 업데이트 함.
- RMSProp (Tieleman and Hinton, 2012)

* AdaGrad
: 현재 및 과거 시점의 gradient의 크기에 영향을 받아서 (첫 번째 빨간 박스)
→ 모수들 각각의 학습률이 결정됨 ( i.e. adaptive learning rate) (두 번째 빨간 박스)

- 학습률이 미리 정해져 있지 않고, 합리적인 방법을 통해 결정된다는 점에서 SGD의 단점 중 1번, 3번이 해결됨
- Goodfellow, I., et al. (2016) Deep Learning : AdaGrad을 수식으로 증명
- 한계 - 지속적인 업데이트가 진행됨에 따라 accumulated squared gradient의 r의 값이 너무 커져서 업데이트가 몇 차례 진행 되지 않아 모수의 추정값이 도중에 수렴해 버림
- Goodfellow, I., et al. (2016) Deep Learning : Adam을 수식으로 증명
- 현재까지 나온 최적화 방법론들 중 일반적으로 빠르게 좋은 추정 값을 찾아 주는 알고리즘.
- Convex loss function 뿐만 아니라 non-convex loss function (예: 딥러닝 모델에서의 손실함수) 에서 매우 좋은 성능을 제공.

'AI > Image' 카테고리의 다른 글
| [Tensorflow-models] hand-pose-detection - 2. Neural Network (1) | 2023.12.27 |
|---|---|
| [Tensorflow-models] pose-detection - 1. Model card (1) | 2023.12.22 |
| [Tensorflow-models] face-landmarks-detection - 1. Model card (0) | 2023.12.22 |
| [Tensorflow-models] hand-pose-detection - 1. Model card (1) | 2023.12.20 |
| [Tensorflow-models] 머신러닝과 딥러닝의 개념 (1) | 2023.12.19 |